Анализ мнений пользователей Твиттера
Задача
Нашим заказчиком является компания IBM - разработчик корпоративного программного обеспечения, который много лет создаёт программные решения для обработки структурированных и неструктурированных данных. Заказчик разработал собственную методологию контент-анализа, и попросил нас создать программное обеспечение, чтобы проверить возможность использования этого подхода для анализа сообщений в Твиттере.
Решение
Мы спроектировали и разработали приложение, которое собирает потоки сообщений по нужной тематике в Твиттере, проводит нормализацию текста, анализирует тональность сообщений и помечает её с помощью специальных меток, затем проводит статистическую обработку результатов анализа и визуализирует статистику за определённый период в режиме реального времени.
Популярность Твиттера среди пользователей делает необходимым анализ больших объёмов потоковых данных. Традиционный подход к обработке такой информации требует наличия большого хранилища данных и большой вычислительной мощности, и обычно не позволяет обрабатывать поступающую информацию и выводить результаты в режиме реального времени. Мы использовали другой подход для эффективной работы с большими данными (Big Data). Согласно этому подходу, из потока отфильтровывается релевантная по тематике часть данных, которая немедленно поступает на анализ. Результаты анализа обработанной части потока доступны пользователю с минимальной задержкой.
Чтобы визуализировать результаты анализа не только в реальном времени, но и в исторической ретроспективе, в проанализированный поток дополнительно внедряются метки времени. По этим меткам поток разбивается на отдельные «окна», что позволяет рассчитывать и выводить статистику не только за весь период сбора данных, но и за заданные интервалы времени.
Разработанный нами механизм обработки сообщений работает как непосредственно с Twitter API, так и с агрегатором GNIP (который предоставляет доступ к потоковым данным не только из Twitter, но и из других социальных приложений и сетей - Facebook, Google+, и др.).
Определение положительных, отрицательных и нейтральных мнений
Определение положительных, отрицательных и нейтральных мнений
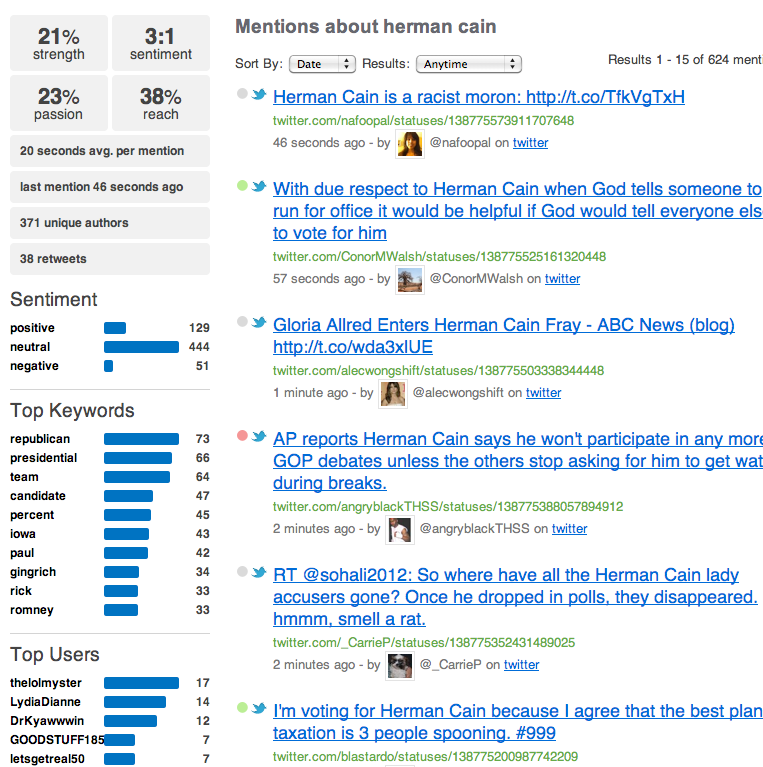
Одной из возможностей применения алгоритмов обработки естественного языка к сообщениям в Твиттере является определение мнений пользователей по выбранной теме.
IBM попросила нас разработать приложение для анализа тональности текста (sentiment analysis) применительно к сообщениям в Твиттере. Программное обеспечение должно находить в сообщениях мнения пользователей Твиттера и определять их эмоциональную окраску (положительная, отрицательная или нейтральная) по отношению к выбранной теме. Такое приложение должно применять анализ тональности к потокам сообщений в Твиттере в режиме реального времени. Целью было использование приложения для автоматизации распознавания, интерпретации и обработки мнений людей в ходе спортивных чемпионатов, политических дебатов, телевизионных шоу и т.д.
IBM предоставила нам разработанный ранее базовый тональный словарь, в котором словам и словосочетаниям соответствовала оценка: нейтральная, положительная или отрицательная. Мы использовали инструментарий IBM LanguageWare для создания на основе этого тонального словаря более точных языковых моделей, способных верно определять тональность сообщений - с учётом выбранной тематики, особенностей лексикона целевой аудитории, идиом, жаргонизмов и прочих устоявшихся выражений, а также языковых конструкций, исключающих возможность «простого» словарного анализа.
Поскольку даже предварительная фильтрация контента не могла гарантировать, что в конкретный момент времени на вход системе не будет подано больше информации, чем она может обработать, компоненты системы были спроектированы и разработаны с возможностью развёртывания в средах для распределённых вычислений – это обеспечивало возможность масштабирования и эластичность решения. Так, например, разработанные лингвистические модели были оформлены как модули UIMA, которые можно запускать с соответствующей обвязкой в различном окружении. Мы успешно использовали в качестве платформ для распределённой обработки потоковых данных IBM InfoSphere Streams и Apache Storm.
Конечной целью проекта было создание программного решения для удобной и наглядной визуализации собранных данных. Приложение отображает результаты анализа потоков сообщений в Твиттере в виде настраиваемых диаграмм, показывающих доли положительных, отрицательных и нейтральных мнений пользователей Твиттера по выбранной тематике. Приложение способно визуализировать данные в режиме реального времени, поэтому отображаемая на диаграммах информация всегда актуальна. Пользователь может визуализировать результаты по всему набору данных, либо ограничить интервал времени для анализируемых сообщений.
Применение
Впервые приложение было использовано для анализа реакции болельщиков Открытого чемпионата США по теннису 2012 года. При этом мнения пользователей Твиттера об играющих участниках отображались на интерактивном табло чемпионата.
В дальнейшем использованная концепция обработки данных была применена и в других сценариях исследования тональности сообщений в Твиттере - например, при анализе отношения аудитории Твиттера к кандидатам на пост президента США в предвыборной кампании 2012 года.