
Что такое Apache NiFi и где его применяют?
Apache NiFi — современный ETL-инструмент* с открытым исходным кодом, к достоинствам которого можно отнести:
- относительную простоту в работе;
- распределенную архитектуру (параллельная загрузка и обработка данных);
- большое количество независимо компилируемых программных модулей;
- версионирование конфигураций.
Этот инструмент предназначен прежде всего для автоматизации обмена данными между программными системами. Когда объемы информации измеряются не десятками гигабайт, а терабайтами, применяется устоявшаяся экосистема с центром в Hadoop (например, в проектах Business Intelligence, где мы работаем с Big Data). NiFi здесь используется, как:
- во-первых, удобный пользовательский интерфейс — из него можно обращаться к разным сервисам более-менее единообразно;
- а во-вторых, механизм организации потоков — если к нескольким сервисам надо обратиться строго поочередно и передать выход одного на вход другого.
Как видим, NiFi — хорошо масштабируемая распределенная система с гарантированной доставкой, умением хранить данные (до выгрузки их другими, более медленными системами) и балансировкой нагрузки. Такая функциональность делает NiFi еще и отличным инструментом для решений в области Internet of Things, где приложения, как правило, работают в условиях нестабильного сетевого окружения. (Подробнее об инструментарии для IoT-проектов мы говорили в предыдущих статьях).
Для справки:
Исходный код Apache NiFi был открыт при передаче технологий NSA в 2014 году, а первое коммерческое программное решение с интегрированным NiFi появилось уже в 2017. Им стала SecureData от Hewlett Packard для Hadoop и IoT. На момент написания статьи для Apache NiFi актуальна версия 1.9.2, выпущенная 8 апреля 2019 под лицензией Apache License 2.0.
Apache NiFi в BI-проектах Программные технологии
Общий подход к обработке данных предполагает, что они подходят под некоторую готовую схему. В работе с нетипизированными данными могут возникнуть сложности, которые каждый инструмент решает по-своему. Например, библиотека Jolt, интегрированная в NiFi, рассчитана на работу с плавающей структурой JSON-ов. Jolt дает возможность посмотреть параметры блока, пример входных данных и прогноз выходных данных сразу на одном экране, что очень удобно.
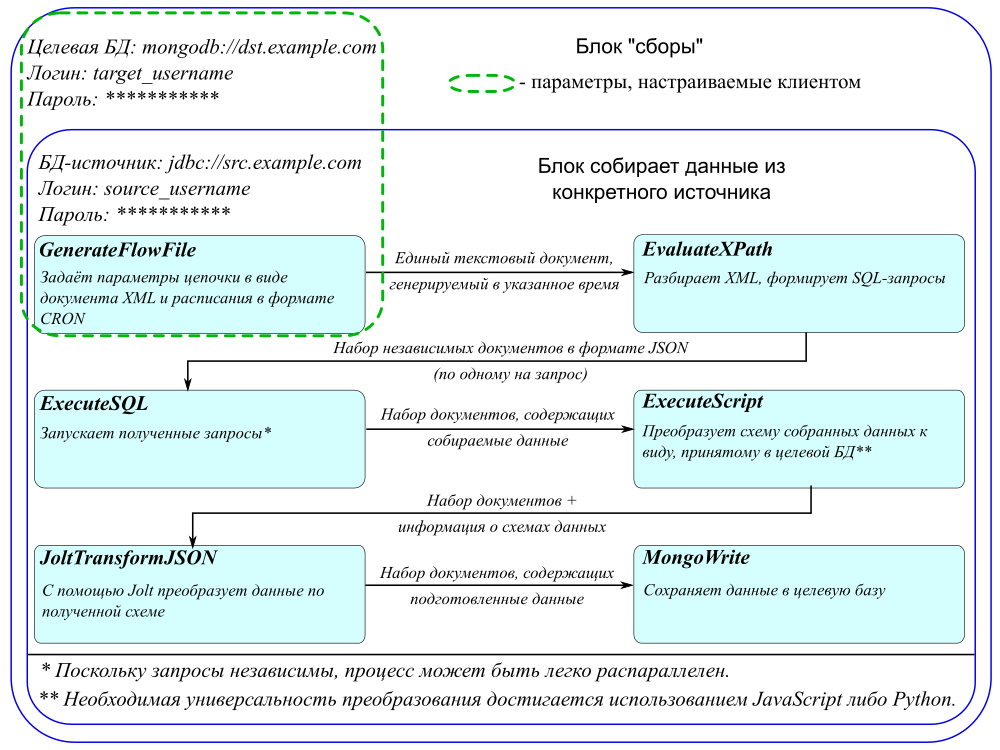
В проектах нам часто приходится собирать сырые данные. Для дальнейшей обработки и анализа мы помещаем их в место, доступное из разных источников (это может быть Postgres, 1С-база или Rest API). Впервые NiFi мы применили в проекте в мае прошлого года, когда встал вопрос об удобном пользовательском интерфейсе.
Apache NiFi запущен на сервере и управляет потоками данных. К нему есть доступ из браузера, где мы указываем:
- источники поступающих данных;
- места, куда нужно складывать данные (в нашем случае это база данных MongoDB);
- какие преобразования необходимо сделать с данными в процессе сбора до этапа сохранения.
Например, мы можем забрать данные SQL-запросом с удаленного сервера и преобразовать их в JSON. JSON преобразовать с помощью Jolt, добавив таким образом служебные данные. Затем поправить схему и сложить полученные данные в нашу Mongo.
Справедливости ради отметим, что NiFi рассчитан на потоковую обработку, а данные в наших проектах в основном поступают пакетно или через полное обновление. Например, может стоять задача записать новые данные поверх старых или собирать информацию один раз в день. К тому же, в наших проектах довольно сложные источники, и сам характер данных не позволяет собирать их потоково. В результате мы используем NiFi, скорее как интерфейс, а сама обработка идет с помощью Spark. Конечно, можно реализовать весь процесс только через NiFi, но в нашем случае это будет значительно сложнее выбранного метода.
StreamSets Data Collector и собственные разработки VS Apache NiFi
Конкурентом NiFi считается StreamSets Data Collector. Мы рассматривали его для решения наших задач, но в SSDC была принципиальная проблема с локализованными данными (в частности, с кириллицей) — нам так и не удалось заставить его использовать нужные кодировки. В NiFi все заработало сразу без дополнительных настроек, за исключением одного случая, в котором мы легко заменили кодировку вручную. Поэтому мы предпочли NiFi.
До NiFi мы использовали собственную разработку на Scala и Spark. Ее существенный недостаток в том, что система полностью управлялась нами. Мы не могли передать заказчику возможность указывать новые источники данных и код обработки, поскольку они жестко прописывались внутри системы. С Apache NiFi интерфейс стал гибким, большую часть дополнений и изменений может делать сам заказчик.
Использовать самописную систему удобно тем, кто ее разрабатывает. Когда мы передаем ее в пользование не программисту, для реализации понятного интерфейса требуются серьезные трудозатраты.
Работа с NiFi: взвешиваем за и против
Как и у любой системы, у NiFi есть свои минусы.
- С точки зрения программиста, способ добавления новых блоков в NiFi несколько перегружен. Инструмент написан на Java, а этот язык в принципе многословен. Еще один момент: неудобный механизм логирования. Если произошла ошибка, ее сложно выловить задним числом. Большинство тяжелых обработок принято ставить на ночь, поэтому момент, где “что-то пошло не так”, мы не увидим, а в результате данные будут собраны неверно или не собраны совсем. Исключить такую ситуацию можно, например, написав код, который будет опрашивать NiFi на предмет возникновения ошибок. Раз в 5 минут данные очищаются, и соответственно, чтобы отследить ошибку, опрашивать систему надо не реже.
- С точки зрения пользователя, проблемой может оказаться общее построение UI. Из-за того, что все операции происходят на сервере, почти каждое действие сопровождается появлением модального окна.
- На стыке интересов пользователей и программистов мы выявили не совсем удобный Rest API. При автоматизации работы с NiFi приходится делать много операций, и они не всегда тривиальны.
С другой стороны, мы для себя нашли много преимуществ применения Apache NiFi.
- Основной плюс NiFi для программистов — открытый исходный код. Любую ошибку можно поправить в локальной копии и пересобрать свой собственный вариант. Если сообщить об ошибке авторам, как правило, в следующей версии она уже будет исправлена. Разработчикам, знающим Java, легко освоить NiFi. При необходимости также несложно применить сторонний обработчик (у нас используется Spark) и встроить его в поток. Этим мы немного усложним разработку, зато упростим работу конечному пользователю и снизим объем запросов по техподдержке. Другое достоинство NiFi — его универсальность. Инструмент собирает разные данные из разных источников, не требуя их предварительной обработки. После чего формируется блок нужного нам вида, с которым можно работать независимо от источника.
- К плюсам для заказчика можно отнести гибкий интерфейс — в нем достаточно просто разобраться на уровне пользователя. Когда возникает необходимость скорректировать готовую цепочку, заказчик может самостоятельно внести изменения. Например, если нужно собрать дополнительную таблицу из имеющейся базы, достаточно открыть конфигурацию в браузере и добавить в нее одну строку. Это быстро и не требует специального образования.
В статье мы рассмотрели только те компоненты NiFi, которые используем в своих проектах, но преимуществ инструмента гораздо больше. К примеру, в NiFi много стандартных компонентов, таких как Jolt, работа с SQL, взаимодействие с сервисами Apache (например, Kafka) и т.д., которые легко используются сразу или после небольшой доработки. Есть встроенная система авторизации с возможностью работать через ActiveDirectory или Kerberos. Кроме того, NiFi можно выкатить на кластер, и для этого не требуется специально разрабатывать механизм взаимодействия. Однако, прежде чем использовать этот инструмент в своих проектах, проверьте, как скажутся его ограничения на вашей разработке.
Ссылки на источник:
Официальный сайт разработчиков Apache NiFi:
http://nifi.apache.org/
Зеркало официального репозитория Apache NiFi:
https://github.com/apache/nifi
Репозиторий Apache NiFi:
https://gitbox.apache.org/repos/asf?p=nifi.git
Сноска:
* ETL (англ. Extract, Transform, Load, рус. “извлечение, преобразование, загрузка”) - процесс обработки изначально разнородных данных для приведения их к виду, применимому в бизнес-модели.


